Sharing Protobuf schemas across services
The system that we're building at Community.com is made of a few services (around fifteen at the time of writing) that interact with each other through a basic version of event sourcing. All events flow (published and consumed) through RabbitMQ and are serialized with Protobuf. With several services already and many more coming in the future, managing the Protobuf schemas becomes a painful part of evolving and maintaining the system. Do we copy the schemas in all services? Do we keep them somewhere and use something akin to Git submodules to keep them in sync in all of our projects? What do we do?! In this post, I'll go through the tooling that we came up with in order to sanely manage our Protobuf schemas throughout our services and technology stack.

This post will go through the steps that led us to the solution we're currently using, so feel free to skip ahead if you just want to know what we ended up with.
Starting out: a single Elixir library
When we started defining schemas for our Protobuf events, we were only using such schemas from Elixir. We created a library called events and started hosting it on our private Hex repository. events contained all the .proto schema files and depended on the exprotobuf library to "compile" the Protobuf schemas to Elixir code. exprotobuf uses a different approach than most Protobuf libraries for other languages that I encountered: it loads the .proto schema definitions at compile time instead of using protoc to compile the Protobuf files to .ex Elixir files. Essentially, we created a module like this:
defmodule Events do
use Protobuf,
from: Path.wildcard(Path.expand("../schemas/*.proto", __DIR__))
endThe most common approach to turning a Protobuf schema into a data structure representable by the programming language you're using is to turn the schema into some kind of "struct" representation. That's exactly what exprotobuf does for Elixir. This is one of our schemas:
# In schemas/event_envelope.proto
syntax = "proto3";
message EventEnvelope {
int64 timestamp = 1;
string source = 2;
}exprotobuf loads this up at compile time and turns it into roughly this Elixir definition:
defmodule Events.EventEnvelope do
defstruct [:timestamp, :source]
# A bunch of encode/decode functions plus
# new/1 to create a new struct.
# ...
endThis whole approach worked okay for a while, but soon we needed to use our Protobuf definitions from a service written in Python.
Sharing Protobuf schemas through Git submodules
The first thing that came to mind when we thought about sharing Protobuf schema definitions across different programming languages was Git submodules. We created a proto_schemas repository containing all the .proto files and added it as a Git submodule to our events Elixir library and to a single Python service. Not much changed on the Elixir side, but on the Python side things were working a bit differently. The Protobuf Python library uses a common approach among Protobuf libraries, which is to use a plugin to the protoc compiler in order to generate Python code from the .proto files. Essentially, you call:
protoc --python_out="." -I ../schemas event_envelope.protoSo, for example, our event_envelope.proto file would become event_envelope.pb2.py once compiled.
The Git-submodule approach worked okay for a while, but it presented two main challenges: how to uniformly version schemas across languages? How to avoid having every project contain a copy of the Protobuf schemas and having to compile them individually to the host language?
Lucky for me, one day I was discussing these problems with my friend Eric from the Elixir team, and we figured out a way to only keep the Protobuf schemas in a single place, compile them all in a single place, but use them from different languages all around.
protoc, CI, and libraries
I did some research on available Protobuf libraries for Elixir and was lucky to find an alternative to exprotobuf called protobuf-elixir. The APIs that this library exposes to manipulate Protobuf structs and manage serialization were exactly the same as the APIs exposed by exprotobuf, so compatibility was not an issue. However, this library had a key features that I was interested in: it supported code generation through the protoc Protobuf compiler. It worked like it does in Python (and many other languages).
protoc --elixir_out=./lib -I ../schemas event_envelope.protoAt this point, I had code generation through protoc working for both Python and Elixir. The next step was to map Protobuf packages (that is, collections of Protobuf schemas) to language libraries and publish those to package repositories for the respective languages. We'll go through what we did for Elixir, but the setup for Python looks almost identical.
All our events-related Protobuf schemas live in the events Protobuf package. So, we decided to map that to an Elixir library called events_schemas. The nice thing about this library is that it only contains the auto-generated code for the Protobuf schemas and nothing else. It essentially exposes an interface to the Protobuf schemas from Elixir. In the same repository where we keep the .proto files, we created a languages/elixir/ directory to store everything necessary for compiling to Elixir and publishing this library on our private hex.pm repository. The "skeleton" of the events_schemas library looks like this:
events_schemas
├── .gitignore
├── lib
│ └── .gitkeep
└── mix.exsBasically, the library is empty. The mix.exs file looks like this:
defmodule EventsSchemas.MixProject do
use Mix.Project
def project do
[
app: :events_schemas,
version: version(),
elixir: "~> 1.8",
deps: deps(),
package: package()
]
end
def application do
[extra_applications: []]
end
defp deps do
[{:protobuf, protobuf_dependency_version()}]
end
defp package do
[
organization: "community",
files: [
"lib/**/*.pb.ex",
"mix.exs",
"VERSION",
"PROTOBUF_EX_VERSION"
]
]
end
defp protobuf_dependency_version do
"PROTOBUF_EX_VERSION" |> File.read!() |> String.trim()
end
defp version do
"VERSION" |> File.read!() |> String.trim()
end
endThere are a couple of peculiar things here. First, we read the version of the library from a magic VERSION file. We keep this file alongside the .proto schemas. This file contains the version of the schemas themselves. Keeping it alongside the schemas means that we can copy it over in the right places when building libraries for different languages so that the events_schemas library can have the same version across all target languages. We copy this file to the root of the events_schemas Elixir directory before building and publishing the library. We use a similar idea for the PROTOBUF_EX_VERSION file. This file contains the version of the protobuf-elixir library that we use. We keep that in a separate file so that we can make sure it's the same between the plugin for the protoc compiler as well as the dependency of the events_schemas library.
Other that the things we just talked about, this looks like a pretty standard mix.exs file. Now, the magic happens in CI.
Concourse CI
Our CI system of choice is Concourse CI. Concourse lets you define pipelines with different steps. Here, we're interested in the last step of our CI pipeline: publishing the libraries for all the languages. Our Concourse pipeline looks like this:
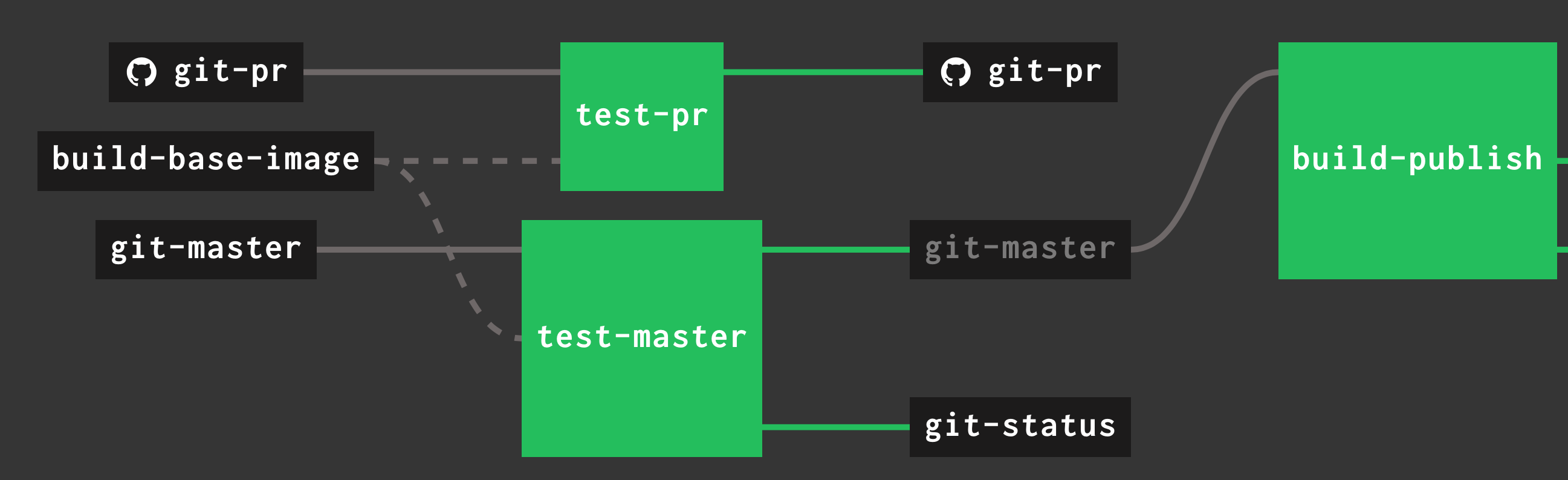
The last step, build-and-publish, is triggered manually by clicking on it and telling it to start. This means that if you want to release a new version of the events_schemas library in all languages, you have to go to Concourse and click this. That's all you need to do. Note that we have Docker containers that build and publish the library for each target language so that we don't have to install anything on the CI system. At this point, Concourse will do the same routine for all target languages:
- Copy all the necessary version files to the right places.
- Generate code for the Protobuf schemas through
protoc. - Publish to the right package repository (for example, hex.pm for Elixir).
That's all. Now, our services can depend on an actual library that contains the auto-generated code representing the Protobuf schemas that we use. However, services don't need to have access to the original .proto files containing the schemas. We're delighted with this system since it feels streamlined and straightforward to use, while providing everything we need.
Encore: multiple Protobuf packages
We moved even a bit further than what I described. In fact, currently we have three Protobuf packages: one for common custom types, one for events, and one for inter-service RPCs. The events and RPC packages both depend on the custom types package. The way we solve the inter-package dependencies is to simply publish the types_schemas libraries first and then depend on that library from the events_schemas and rpc_schemas libraries. For example, in Elixir we changed the mix.exs file we looked at earlier (for the events_schemas library) and added the dependency:
defp deps do
[
{:protobuf, protobuf_dependency_version()},
{:types_schemas, "0.1.0", organization: "community"}
]
endConclusion
To recap, our Protobuf pipeline and workflow currently work like this. First, you make changes to a Protobuf schema. Then, you bump a version in a file. Then, you push those changes up to GitHub. Once CI makes sure you didn't break anything, you log into Concourse and kick-start the build-and-publish task. A new version of the right library gets published to different package repositories for different languages. It's not the simplest system, but the workflow is easy to use and effective. Most of all, this workflow can apply to most programming languages and make it easier to manage versioning and evolving shared collections of Protobuf schemas.